Blog 5: Studying for AWS Certified Cloud Practitioner pt.6

Intro and Recap
Hello again! This week we are continuing our discussion of the material that will most likely appear in the AWS Certified Cloud Pracitioner (CCP) Exam. Last time we went over a part of the fifth module, Networking and Content Delivery, and briefly discussed the services of VPC, Route 53, and CloudFront. In this post, we’ll keep talking about a main service category: Compute. Let’s get started!
Compute
In this module, you learn about one of the most widely used category of services in the AWS portfolio: compute. Along with compute, storage and database are the core tenets of the AWS platform. In fact, EC2, along with S3 and RDS, were the first services that AWS offered when they launched in 2006. If you’re curious, here’s a nice little article of how AWS came about which I came across while researching for this post.
Compute services can be divided into 4 categories: IaaS, serverless, container-based, and PaaS. Today, I’ll only be touching upon IaaS (EC2) and serverless (Lambda). Take a look at the graphic below for a quick comparison of the categories. When selecting a compute service, you should consider your app’s design, the usage patterns, and how much configuration settings you want to manage yourself. Picking the wrong compute solution for your architecture can lead to performance, availability, or deployment issues, so choose wisely!
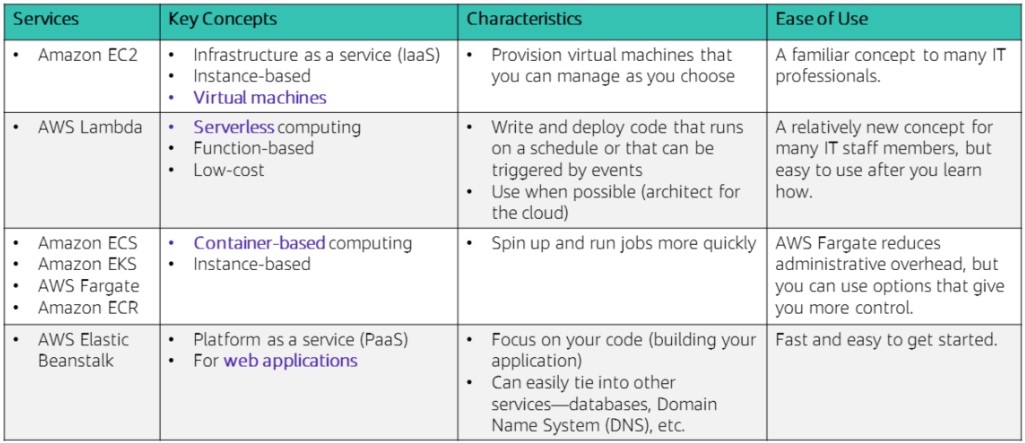
Categorizing compute services
EC2
EC2, or Elastic Compute Cloud, provides you with virtual machines, called instances, in the cloud. Since EC2 is IaaS, it gives you full control over the guest OS on each instance, the traffic that goes to and from instances, where you want to launch the instance, and more infra-related management options. To launch an instance, you’ll have to make a number of choices. If you’re using the Management Console (GUI), you can have the Launch Instance Wizard guide you through the process. These are the things you’ll have to make decisions on:
- AMI
- instance type
- network settings
- IAM role (optional)
- user data (optional)
- storage options
- tags (optional)
- security group
- key pair
First is the AMI, or Amazon Machine Image. This is somewhat equivalent to an ISO that you would typically use for VMs, although AMIs have more to them besides just the OS. They are VM templates and include 3 parts: the template for the root volume of the instance (which includes the OS and everything installed in it), the launch permissions that control which AWS accounts can use the AMI, and the block device mapping that specifies the volumes to attach to the instance (if any). Next is the instance type. Choose a type based off your needs in memory, processing power, disk space and type, and network performance. For more info and help in choosing a type, visit the details page and explorer. In network settings, you’ll define things like where the instance should be deployed and if it should automatically be assigned a public IP. The next 2 steps, IAM role and user data, are optional. Choose/create an IAM role if you need the EC2 to have permission and interact with other AWS services. User data is a script that gets executed when the instance first launches. After that, select your storage options, including root volumes and additional storage. Next, define tags to help you identify your instance. Then, choose/create a security group to manage what’s allowed to access your instace. Finally, pick a key pair to log into your instance. Make sure that you have the key pair downloaded and in a safe and secure location. Once you’ve downloaded it, you won’t be able to see it again. If you lost the key pair, you’ll have to replace it or create an AMI of the existing instance, launch a new instance using the AMI, and select a new key pair. Follow the information here for help. By the way, my menmonic for this list is: “All Ingenious Newts Inside Uganda Start To Secure Group Keys”. It’s fun and wacky and sounds like I’m commanding an army of newts. 😂
EC2 Cost Optimization
We talked about the different decisions to make when you launch your instance, but there’s actually another thing to think about when creating and deploying instances: how you’ll run your instances. More specifically, the different pricing models that are offered for EC2. There are 6 different pricing models to choose from: on-demand instances, dedicated hosts, dedicated instances, reserved instances, scheduled reserved instances, and spot instances. With on-demand, you pay by the hour and have no long term commitments. The trade-off is that this is a fairly expensive way to run your instances. Dedicated hosts are physical servers with EC2 capacity fully dedicated for your use. Dedicated instances are instances that run in a VPC on hardware that’s dedicated to a single customer. Reserved instances have been discussed before in the second blog about Cloud Economics and Billing since they are a cheaper way to run instances because of the required commitment. Scheduled reserved instances are for purchasing a capacity reservation that’s always available on either a daily, weekly, or monthly basis that you choose. Lastly, spot instances allow you to bid on unused EC2 capacity. Your spot instances run as long as they’re available and your bid is above the spot instance price. They are more volatile because they can be interrupted by AWS with a 2 minute notification. Look at the graphics below for a quick comparison of the pricing models.
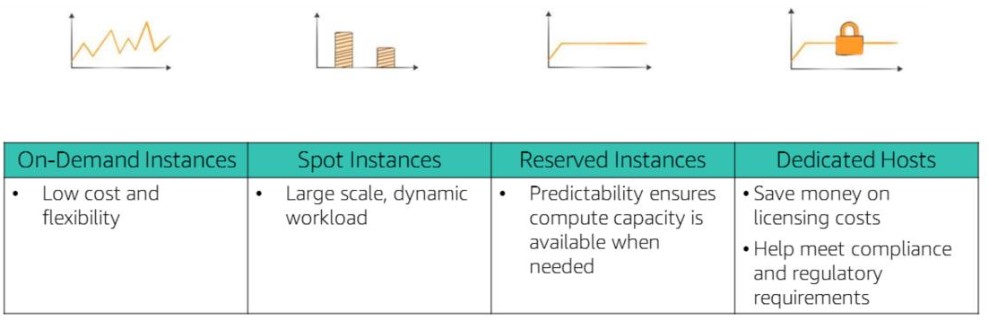
Benefits of the different EC2 pricing models
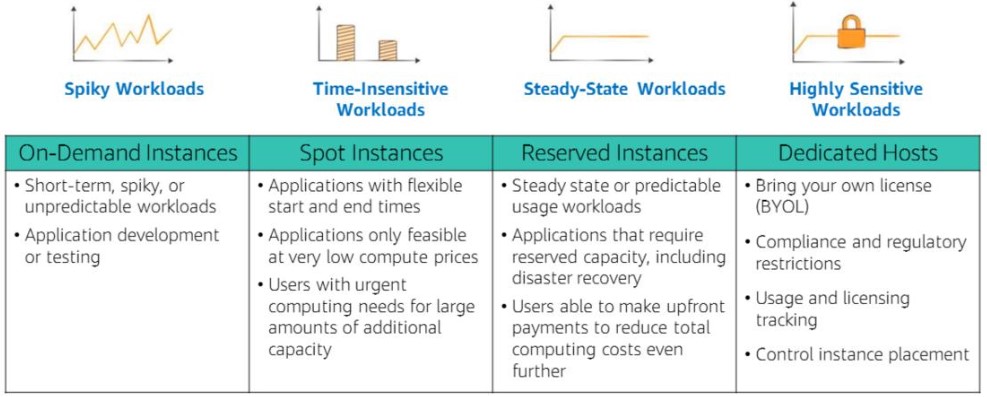
Use cases of the different EC2 pricing models
Lambda
Many say that the next wave of cloud computing is serverless computing. This is where you run code without worrying about servers, clusters, or any of the underlying infrastructure required to do so. While serverless is a fantastic advancement, it doesn’t work for every application or architecture. So before you go all in on it, think about if it’s right for your use case. With that out of the way, let’s talk more specifically about Lambda, AWS’ serverless computing offering.
Lambda allows you to run your code, called a lambda function, on either a schedule or in response to events. Lambda functions can be triggered by different “event sources” like AWS services or developer-created applications. To have a function be triggered, you can have an AWS service (like S3 or SNS) publish events to Lambda, have Lambda pull events from a service (like SQS or DynamoDB), have a service invoke the function directly (like API Gateway or an Application Load Balancer), or, of course, manually invoke it through the Lambda Console, AWS CLI, or using the SDK.
Take a look at the images below for examples of schedule-based and event-based Lambda functions.
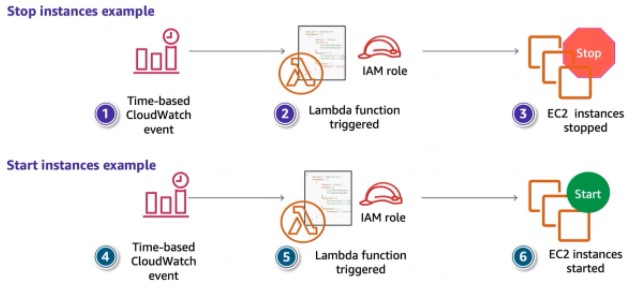
Example of Lambda function that is triggered based on schedule. It starts and stops EC2 instances during the business working hours
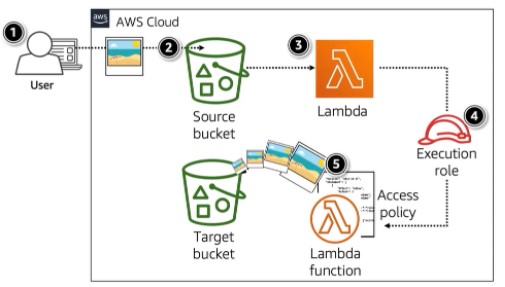
Example of Lambda function that is triggered based on an event. This shows that when a user uploads an object to an S3 bucket, S3 publishes the event to Lambda, triggering a Lambda function that will read the object and create and save a thumbnail of the object to the target S3 bucket
Next Time
Hope you learned a lot today. We’ll continue the AWS CCP discussion next week.
More Info
AWS Academy Cloud Foundations course
Note: Assets in this post are from AWS Academy’s Cloud Foundations course